The Human Genome Project pieced together only 92% of the DNA – now scientists have finally filled in the remaining 8%
Advances in technology have enabled researchers to sequence the large regions of repetitive DNA that eluded the Human Genome Project.
- 4 April 2022
- 7 min read
- by The Conversation

When the Human Genome Project announced that they had completed the first human genome in 2003, it was a momentous accomplishment - for the first time, the DNA blueprint of human life was unlocked. But it came with a catch - they weren’t actually able to put together all the genetic information in the genome. There were gaps: unfilled, often repetitive regions that were too confusing to piece together.
With advancements in technology that could handle these repetitive sequences, scientists finally filled those gaps in May 2021, and the first end-to-end human genome was officially published on Mar. 31, 2022.
I am a genome biologist who studies repetitive DNA sequences and how they shape genomes throughout evolutionary history. I was part of the team that helped characterize the repeat sequences missing from the genome. And now, with a truly complete human genome, these uncovered repetitive regions are finally being explored in full for the first time.
When Human Genome Project researchers announced they had successfully completed sequencing the human genome, it was only about 92% complete. There were still hundreds of gaps or missing DNA sequences. Why was it so difficult to complete the sequence? Let’s break it down! #T2T pic.twitter.com/2RXDJUNdXM
— National Human Genome Research Institute (@genome_gov) July 15, 2021
The missing puzzle pieces
German botanist Hans Winkler coined the word “genome” in 1920, combining the word “gene” with the suffix “-ome,” meaning “complete set,” to describe the full DNA sequence contained within each cell. Researchers still use this word a century later to refer to the genetic material that makes up an organism.
One way to describe what a genome looks like is to compare it to a reference book. In this analogy, a genome is an anthology containing the DNA instructions for life. It’s composed of a vast array of nucleotides (letters) that are packaged into chromosomes (chapters). Each chromosome contains genes (paragraphs) that are regions of DNA which code for the specific proteins that allow an organism to function.
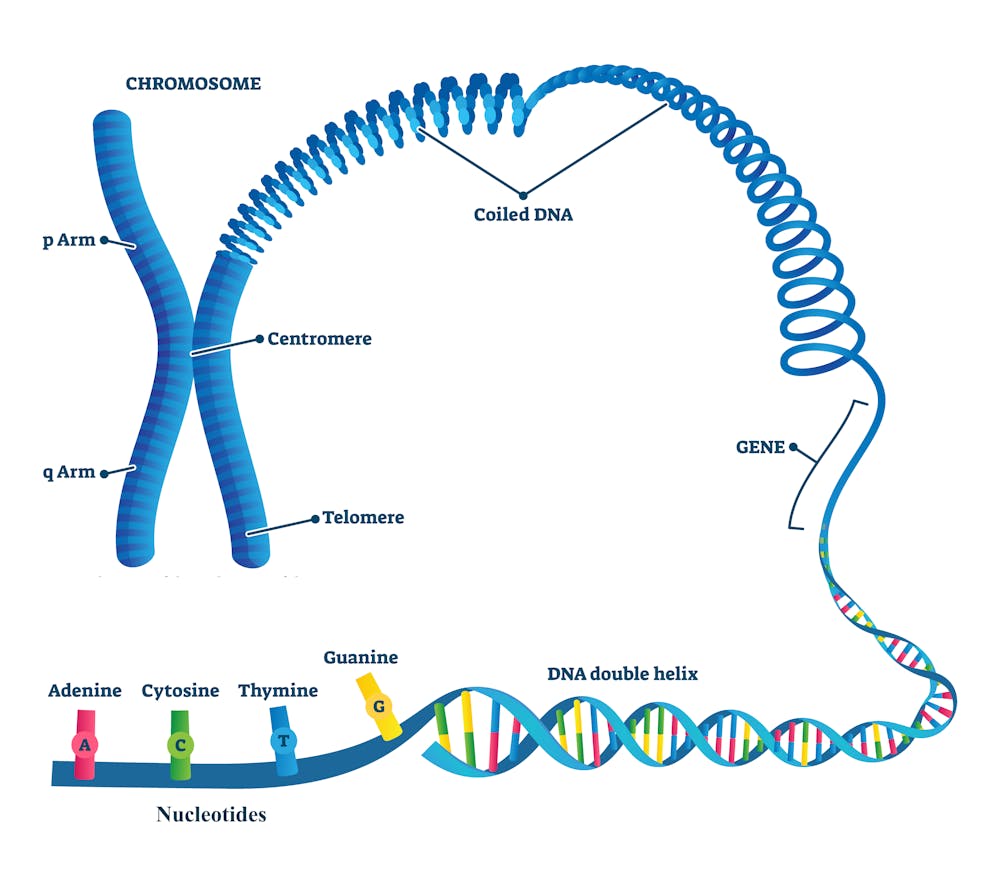
While every living organism has a genome, the size of that genome varies from species to species. An elephant uses the same form of genetic information as the grass it eats and the bacteria in its gut. But no two genomes look exactly alike. Some are short, like the genome of the insect-dwelling bacteria Nasuia deltocephalinicola with just 137 genes across 112,000 nucleotides. Some, like the 149 billion nucleotides of the flowering plant Paris japonica, are so long that it’s difficult to get a sense of how many genes are contained within.
But genes as they’ve traditionally been understood – as stretches of DNA that code for proteins – are just a small part of an organism’s genome. In fact, they make up less than 2% of human DNA.
The human genome contains roughly 3 billion nucleotides and just under 20,000 protein-coding genes - an estimated 1% of the genome’s total length. The remaining 99% is non-coding DNA sequences that don’t produce proteins. Some are regulatory components that work as a switchboard to control how other genes work. Others are pseudogenes, or genomic relics that have lost their ability to function.
And over half of the human genome is repetitive, with multiple copies of near-identical sequences.
What is repetitive DNA?
The simplest form of repetitive DNA are blocks of DNA repeated over and over in tandem called satellites. While how much satellite DNA a given genome has varies from person to person, they often cluster toward the ends of chromosomes in regions called telomeres. These regions protect chromosomes from degrading during DNA replication. They’re also found in the centromeres of chromosomes, a region that helps keep genetic information intact when cells divide.
Have you read?
Researchers still lack a clear understanding of all the functions of satellite DNA. But because satellite DNA forms unique patterns in each person, forensic biologists and genealogists use this genomic “fingerprint” to match crime scene samples and track ancestry. Over 50 genetic disorders are linked to variations in satellite DNA, including Huntington’s disease.
Another abundant type of repetitive DNA are transposable elements, or sequences that can move around the genome.
Some scientists have described them as selfish DNA because they can insert themselves anywhere in the genome, regardless of the consequences. As the human genome evolved, many transposable sequences collected mutations repressing their ability to move to avoid harmful interruptions. But some can likely still move about. For example, transposable element insertions are linked to a number of cases of hemophilia A, a genetic bleeding disorder.
But transposable elements aren’t just disruptive. They can have regulatory functions that help control the expression of other DNA sequences. When they’re concentrated in centromeres, they may also help maintain the integrity of the genes fundamental to cell survival.
They can also contribute to evolution. Researchers recently found that the insertion of a transposable element into a gene important to development might be why some primates, including humans, no longer have tails. Chromosome rearrangements due to transposable elements are even linked to the genesis of new species like the gibbons of southeast Asia and the wallabies of Australia.
Completing the genomic puzzle
Until recently, many of these complex regions could be compared to the far side of the moon: known to exist, but unseen.
When the Human Genome Project first launched in 1990, technological limitations made it impossible to fully uncover repetitive regions in the genome. Available sequencing technology could only read about 500 nucleotides at a time, and these short fragments had to overlap one another in order to recreate the full sequence. Researchers used these overlapping segments to identify the next nucleotides in the sequence, incrementally extending the genome assembly one fragment at a time.
These repetitive gap regions were like putting together a 1,000-piece puzzle of an overcast sky: When every piece looks the same, how do you know where one cloud starts and another ends? With near-identical overlapping stretches in many spots, fully sequencing the genome by piecemeal became unfeasible. Millions of nucleotides remained hidden in the the first iteration of the human genome.
Since then, sequence patches have gradually filled in gaps of the human genome bit by bit. And in 2021, the Telomere-to-Telomere (T2T) Consortium, an international consortium of scientists working to complete a human genome assembly from end to end, announced that all remaining gaps were finally filled.
This was made possible by improved sequencing technology capable of reading longer sequences thousands of nucleotides in length. With more information to situate repetitive sequences within a larger picture, it became easier to identify their proper place in the genome. Like simplifying a 1,000-piece puzzle to a 100-piece puzzle, long-read sequences made it possible to assemble large repetitive regions for the first time.
With the increasing power of long-read DNA sequencing technology, geneticists are positioned to explore a new era of genomics, untangling complex repetitive sequences across populations and species for the first time. And a complete, gap-free human genome provides an invaluable resource for researchers to investigate repetitive regions that shape genetic structure and variation, species evolution and human health.
But one complete genome doesn’t capture it all. Efforts continue to create diverse genomic references that fully represent the human population and life on Earth. With more complete, “telomere-to-telomere” genome references, scientists’ understanding of the repetitive dark matter of DNA will become more clear.
[Get fascinating science, health and technology news. Sign up for The Conversation’s weekly science newsletter.]![]()
Authors
Gabrielle Hartley, PhD Candidate in Molecular and Cell Biology, University of Connecticut
![]()
This article is republished from The Conversation under a Creative Commons license. Read the original article.
Disclosure statement
Gabrielle Hartley receives funding from the National Science Foundation.
Partners
![]()
University of Connecticut provides funding as a member of The Conversation US.
More from The Conversation




Recommended for you




